Classification via Minimum Incremental Coding Length
Abstract
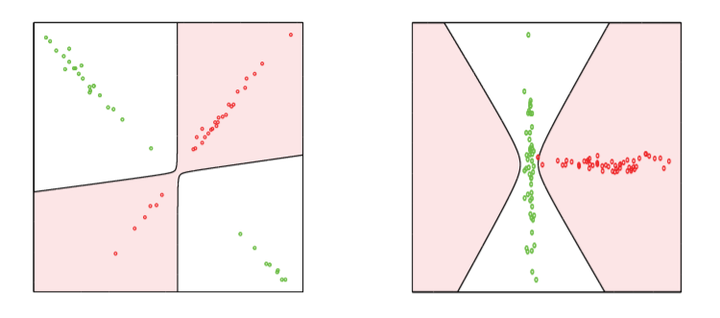
We present a simple new criterion for classification, based on principles from lossy data compression. The criterion assigns a test sample to the class that uses the minimum number of additional bits to code the test sample, subject to an allowable distortion. We demonstrate the asymptotic optimality of this criterion for Gaussian distributions and analyze its relationships to classical classifiers. The theoretical results clarify the connections between our approach and popular classifiers such as maximum a posteriori (MAP), regularized discriminant analysis (RDA), k-nearest neighbor (k-NN), and support vector machine (SVM), as well as unsupervised methods based on lossy coding. Our formulation induces several good effects on the resulting classifier. First, minimizing the lossy coding length induces a regularization effect which stabilizes the (implicit) density estimate in a small sample setting. Second, compression provides a uniform means of handling classes of varying dimension. The new criterion and its kernel and local versions perform competitively on synthetic examples, as well as on real imagery data such as handwritten digits and face images. On these problems, the performance of our simple classifier approaches the best reported results, without using domainspecific information.