Robust 3D Human Pose Estimation from a Single Image or a Video Sequence
Abstract
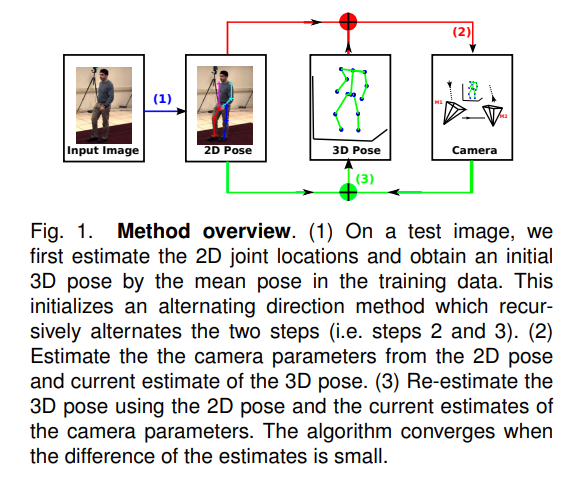
We propose a method for estimating 3D human poses from single images or video sequences. The task is challenging because: (a) many 3D poses can have similar 2D pose projections which makes the lifting ambiguous, and (b) current 2D joint detectors are not accurate which can cause big errors in 3D estimates. We represent 3D poses by a sparse combination of bases which encode structural pose priors to reduce the lifting ambiguity. This prior is strengthened by adding limb length constraints. We estimate the 3D pose by minimizing an L1L1 norm measurement error between the 2D pose and the 3D pose because it is less sensitive to inaccurate 2D poses. We modify our algorithm to output KK 3D pose candidates for an image, and for videos, we impose a temporal smoothness constraint to select the best sequence of 3D poses from the candidates. We demonstrate good results on 3D pose estimation from static images and improved performance by selecting the best 3D pose from the KK proposals. Our results on video sequences also show improvements (over static images) of roughly 15%.