Tensor LRR and Sparse Coding Based Subspace Clustering
Abstract
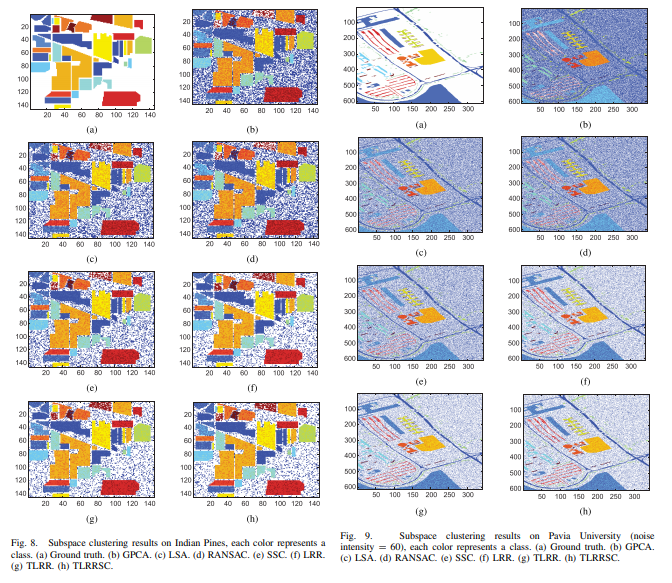
Subspace clustering groups a set of samples from a union of several linear subspaces into clusters, so that the samples in the same cluster are drawn from the same linear subspace. In the majority of the existing work on subspace clustering, clusters are built based on feature information, while sample correlations in their original spatial structure are simply ignored. Besides, original high-dimensional feature vector contains noisy/redundant information, and the time complexity grows exponentially with the number of dimensions. To address these issues, we propose a tensor low-rank representation (TLRR) and sparse coding-based (TLRRSC) subspace clustering method by simultaneously considering feature information and spatial structures. TLRR seeks the lowest rank representation over original spatial structures along all spatial directions. Sparse coding learns a dictionary along feature spaces, so that each sample can be represented by a few atoms of the learned dictionary. The affinity matrix used for spectral clustering is built from the joint similarities in both spatial and feature spaces. TLRRSC can well capture the global structure and inherent feature information of data and provide a robust subspace segmentation from corrupted data. Experimental results on both synthetic and real-world data sets show that TLRRSC outperforms several established state-of-the-art methods.