Neural Multimodal Cooperative Learning Towards Micro-video Understanding
Abstract
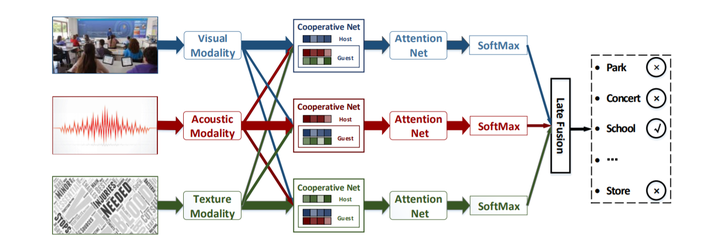
The prevailing characteristics of micro-videos result in the less descriptive power of each modality. The micro-video representations, several pioneer efforts proposed, are limited in implicitly exploring the consistency between different modality information but ignore the complementarity. In this paper, we focus on how to explicitly separate the consistent features and the complementary features from the mixed information and harness their combination to improve the expressiveness of each modality. Towards this end, we present a Neural Multimodal Cooperative Learning model (NMCL) to split the consistent component and the complementary component by a novel relation-aware attention mechanism. Specifically, the computed attention score can be used to measure the correlation between the features extracted from different modalities. And then, a threshold is learned for each modality to distinguish the consistent and complementary features, according to the score. Thereafter, we integrate the consistent parts to enhance the representations and supplement the complementary ones to reinforce the information in each modality. As to the problem of redundant information, which may cause overfitting and is hard to distinguish, we devise an attention network to dynamically capture the features which closely related the category and output a discriminative representation for prediction. Experimental results on a real-world micro-video dataset show that NMCL outperforms state-of-the-art methods. Further studies verify the effectiveness and cooperative effects brought by the attentive mechanism.