Multi-view Common Space Learning for Emotion Recognition in the Wild
Abstract
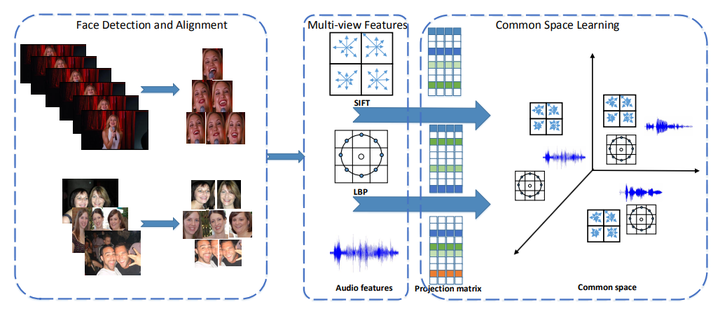
It is a very challenging task to recognize emotion in the wild. Recently, combining information from various views or modalities has attracted more attention. Cross modality features and features extracted by different methods are regarded as multi-view information of the sample. In this paper, we propose a method to analyse multi-view features of emotion samples and automatically recognize the expression as part of the fourth Emotion Recognition in the Wild Challenge (EmotiW 2016). In our method, we first extract multi-view features such as BoF, CNN, LBP-TOP and audio features for each expression sample. Then we learn the corresponding projection matrices to map multi-view features into a common subspace. In the meantime, we impose `2,1-norm penalties on projection matrices for feature selection. We apply both this method and PLSR to emotion recognition. We conduct experiments on both AFEW and HAPPEI datasets, and achieve superior performance. The best recognition accuracy of our method is 55.31% on the AFEW dataset for video based emotion recognition in the wild. The minimum RMSE for group happiness intensity recognition is 0.9525 on HAPPEI dataset. Both of them are much better than that of the challenge baseline.