Abstract
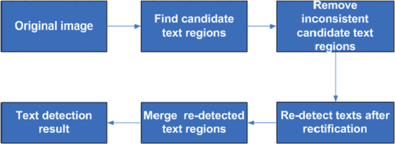
Automatically extracting texts from natural images is very useful for many applications such as augmented reality. Most of the existing text detection systems require that the texts to be detected (and recognized) in an image are taken from a nearly frontal viewpoint. However, texts in most images taken naturally by a camera or a mobile phone can have a significant affine or perspective deformation, making the existing text detection and the subsequent OCR engines prone to failures. In this paper, based on stroke width transform and texture invariant low-rank transform, we propose a framework that can detect and rectify texts in arbitrary orientations in the image against complex backgrounds, so that the texts can be correctly recognized by common OCR engines. Extensive experiments show the advantage of our method when compared to the state of art text detection systems.