Locality-constrained Linear Coding Based Bi-layer Model for Multi-view Facial Expression Recognition
Abstract
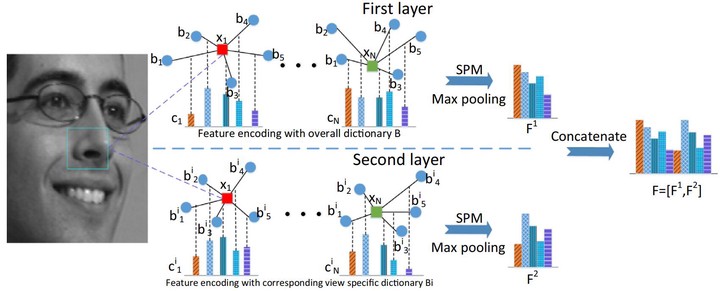
Multi-view facial expression recognition is a challenging and active research area in computer vision. In this paper, we propose a simple yet effective method, called the locality-constrained linear coding based bi-layer (LLCBL) model, to learn discriminative representation for multi-view facial expression recognition. To address the issue of large pose variations, locality-constrained linear coding is adopted to construct an overall bag-of-features model, which is then used to extract overall features as well as estimate poses in the first layer. In the second layer, we establish one specific view-dependent model for each view, respectively. After the pose information of the facial image is known, we use the corresponding view-dependent model in the second layer to further extract features. By combining all the features in these two layers, we obtain a unified representation of the image. To evaluate the proposed approach, we conduct extensive experiments on both BU-3DFE and Multi-PIE databases. Experimental results show that our approach outperforms the state-of-the-art methods.