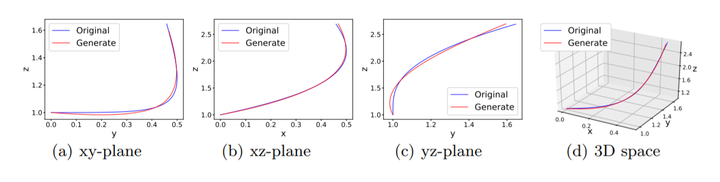
Abstract
Neural networks have been very successful in many learning tasks, for their powerful ability to fit the data. Recently, to understand the success of neural networks, much attention has been paid to the relationship between differential equations and neural networks. Some research suggests that the depth of neural networks is important for their success. However, the understanding of neural networks from the differential equation perspective is still very preliminary. In this work, also connecting with the differential equation, we extend the depth of neural networks to infinity, and remove the existing constraint that parameters of every layer have to be the same by using another ordinary differential equation(ODE) to model the evolution of the weights. We prove that the ODE can model any continuous evolutionary weights and validate it by an experiment. Meanwhile, we propose a new training strategy to overcome the inefficiency of pure adjoint method. This strategy allows us to further understand the relationship between ResNet with finite layers and that with infinite layers. Our experiment indicates that the former can be a good initialization of the latter. Finally, we give a heuristic explanation on why the new training method works better than pure adjoint method. Further experiments show that our neural ODE with evolutionary weights converges faster than that with fixed weights.