Joint Dictionary Learning and Semantic Constrained Latent Subspace Projection for Cross-Modal Retrieval
Abstract
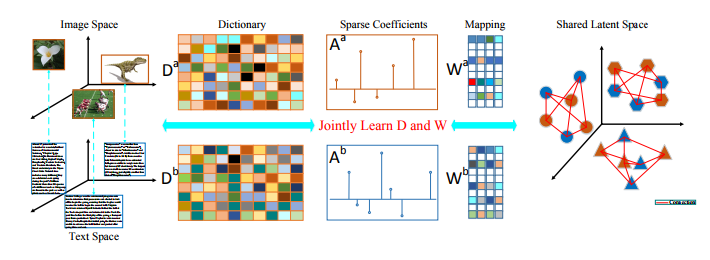
With the increasing of multi-modal data on the internet, crossmodal retrieval has received a lot of attention in recent years. It aims to use one type of data as query and retrieve results of another type. For different modality data, how to reduce their heterogeneous property and preserve their local relationship are two main challenges. In this paper, we present a novel joint dictionary learning and semantic constrained latent subspace learning method for cross-modal retrieval (JDSLC) to deal with above two issues. In this unified framework, samples from different modalities are encoded by their corresponding dictionaries to reduce the semantic gap. In the meantime, we learn modality-specific projection matrices to map the sparse coefficients into the shared latent subspace. Meanwhile, we impose a novel cross-modal similarity constraint to make the representations of samples that belong to same class but from different modalities as close as possible in the latent subspace. An efficient algorithm is proposed to jointly optimize the proposed model and learn the optimal dictionary, coefficients and projection matrix for each modality. Extensive experimental results on multiple benchmark datasets show that our proposed method outperforms the state-of-the-art approaches.