Optimization Algorithm Inspired Deep Neural Network Structure Design
Abstract
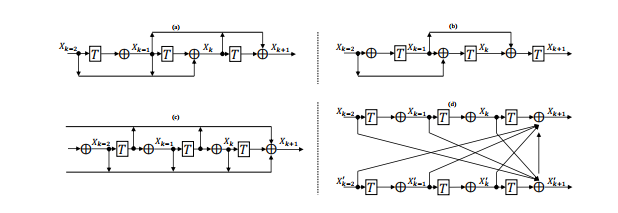
Deep neural networks have been one of the dominant machine learning approaches in recent years. Several new network structures are proposed and have better performance than the traditional feedforward neural network structure. Representative ones include the skip connection structure in ResNet and the dense connection structure in DenseNet. However, it still lacks a unified guidance for the neural network structure design. In this paper, we propose the hypothesis that the neural network structure design can be inspired by optimization algorithms and a faster optimization algorithm may lead to a better neural network structure. Specifically, we prove that the propagation in the feedforward neural network with the same linear transformation in different layers is equivalent to minimizing some function using the gradient descent algorithm. Based on this observation, we replace the gradient descent algorithm with the heavy ball algorithm and Nesterov’s accelerated gradient descent algorithm, which are faster and inspire us to design new and better network structures. ResNet and DenseNet can be considered as two special cases of our framework. Numerical experiments on CIFAR-10, CIFAR-100 and ImageNet verify the advantage of our optimization algorithm inspired structures over ResNet and DenseNet.