Towards Improving the Consistency, Efficiency, and Flexibility of Differentiable Neural Architecture Search
Abstract
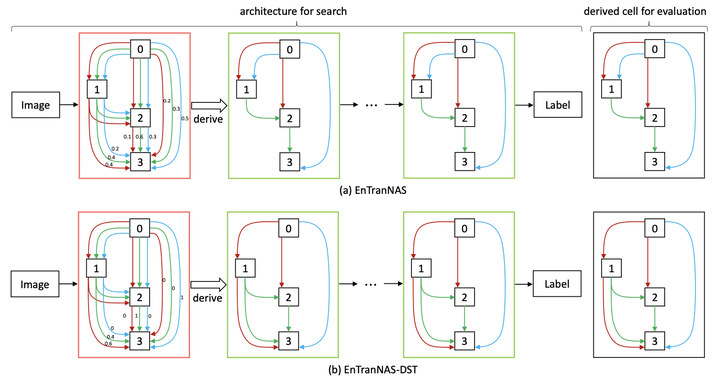
Most differentiable neural architecture search methods construct a super-net for search and derive a target-net as its sub-graph for evaluation. There exists a significant gap between the architectures in search and evaluation. As a result, current methods suffer from an inconsistent, inefficient, and inflexible search process. In this paper, we introduce EnTranNAS that is composed of Engine-cells and Transit-cells. The Engine-cell is differentiable for architecture search, while the Transit-cell only transits a sub-graph by architecture derivation. Consequently, the gap between the architectures in search and evaluation is significantly reduced. Our method also spares much memory and computation cost, which speeds up the search process. A feature sharing strategy is introduced for more balanced optimization and more efficient search. Furthermore, we develop an architecture derivation method to replace the traditional one that is based on a hand-crafted rule. Our method enables differentiable sparsification, and keeps the derived architecture equivalent to that of Engine-cell, which further improves the consistency between search and evaluation. Besides, it supports the search for topology where a node can be connected to prior nodes with any number of connections, so that the searched architectures could be more flexible. For experiments on CIFAR-10, our search on the standard space requires only 0.06 GPU-day. We further have an error rate of 2.22% with 0.07 GPU-day for the search on an extended space. We can also directly perform the search on ImageNet with topology learnable and achieve a top-1 error rate of 23.8% in 2.1 GPU-day.